我是创新港管理学博士,我来分享下我和gpt的日常。这个帖子我会一直更新,欢迎讨论。或者来含英楼5楼做客一起讨论。
最近网易云音乐和QQ音乐带头推出了年度报告,知乎 也会出今年的报告,逼得我不得不写完这个选题了…尽管没有人会真正关心别人的报告,但年度报告作为一种仪式感,哪怕只是自娱自乐也会让我们有阶段性的获得感,所以每次到年底都会被各种 App 刷屏。

其实年度报告就是某种程度的数据分析——提供全年的数据汇总,提供简要的分析结果,得出几个有噱头的结论。普通人很难自己完成这样的数据分析,因为我们既没有数据,也没有分析能力。 前几天,在朋友圈看到有人用 ChatGPT 做 Github 年终报告:

所以今年,我打算赶在知乎的年终报告之前,让 ChatGPT 帮我生成自己的知乎年终报告。不过 ChatGPT/NewBing 并不能直接访问到知乎页面(Github 可以),所以我们还需要自己准备数据。

爬取知乎数据爬虫自然也要 ChatGPT 来写,我们给 AI 打下手。现在的爬虫教程真好写,只需要写 prompt,过程都是 AI 做。 第一步:确定抓取入口个人主页里的数据不全,所以我选择用创作中心的数据。需要注意的是,知乎的想法、文章、回答、视频、提问的互动数据字段并不一样,具体解析 JSON 的时候会比较麻烦,需要一些手动的修改。我在这里以抓取回答为例,后面会给出全部内容的代码。 点开 F12 浏览器控制台,下滑加载一部分新数据,找到这一条:
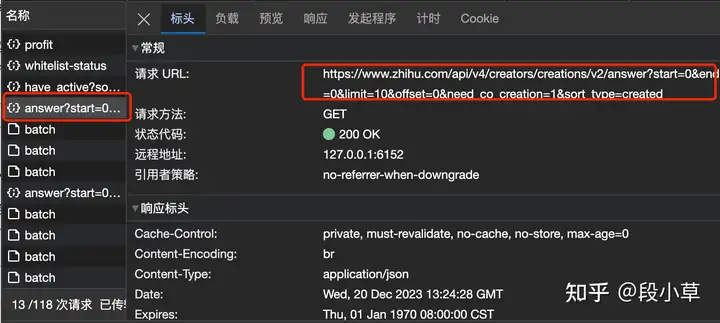
这一条,就够了。 第二步:让 ChatGPT 写代码我们要提供给 ChatGPT 的,分别是 CURL 代码和这个请求返回的文本,也就是在浏览器里右键-复制为 cURL 和复制响应:
然后打开 ChatGPT,为了避免它不认真干活,老规矩先 COT 三连: -think step by step-i will tip $200 if you do well-i have no fingers
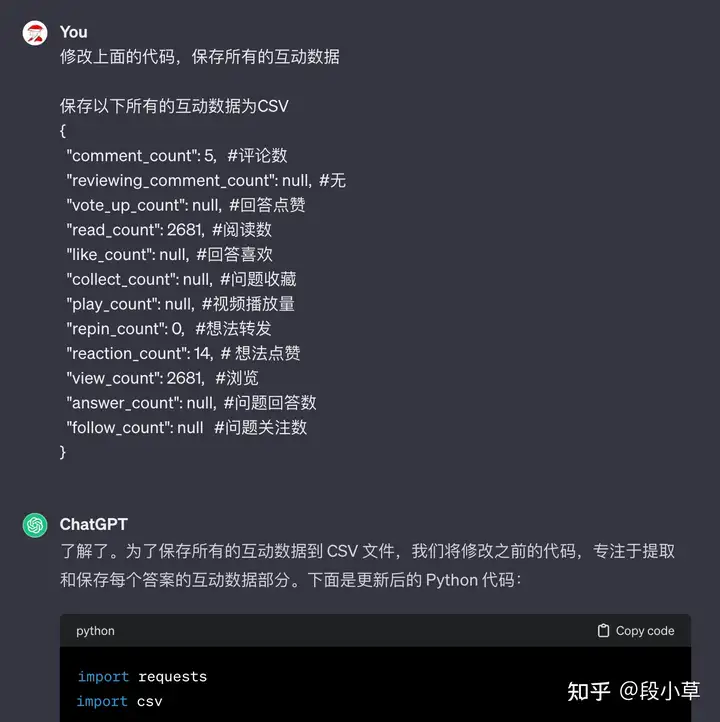
然后提出我们的要求(其实分步骤做大家也更容易理解,但…ChatGPT 理解能力很强,我给它的任务它一次性就能完成。我直接拆解我的 prompt,大家看懂了 prompt,也就理解了爬虫代码的思路):根据以下 CURL 请求和返回的JSON文本完成爬虫代码,要求:1、把CURL改写成Python requests代码2、正确解析返回内容,**注意**必须将所有有意义的互动数据全部保存3、写出循环,请求所有数据,每次循环停留 3s(offset从0开始)4、将得到的所有数据保存到一个 CSV 文件中你不需要解释代码,请一次性返回**所有代码**,你不需要运行代码,我会把代码保存到本地运行(粘贴上面复制的 CURL 和响应内容)
注意,这里会包含你知乎的 cookies,理论上会有一定的风险。正确做法是在 CURL 中删除 cookies,之后代码里手动补上。

生成的代码只需要做很少的修改就能用,如果有报错或者其他修改的需求,也可以让 ChatGPT 再做修改:
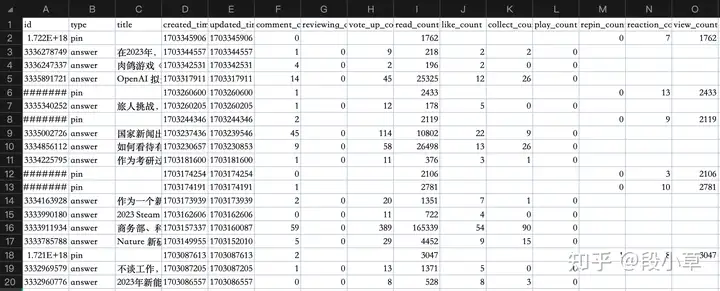
节约篇幅,我直接粘上最后的代码(里面的注释都是 ChatGPT 写的): import requestsimport csvimport time# 初始化变量base_url = 'https://www.zhihu.com/api/v4/creators/creations/v2/all'params = { 'start': 0, 'end': 0, 'limit': 10, # 你可以调整这个参数以获取更多或更少的记录 'offset': 0, 'need_co_creation': 1, 'sort_type': 'created'}headers = { 'authority': 'www.zhihu.com', 'accept': '*/*', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'referer': 'https://www.zhihu.com/creator/manage/creation/answer', 'sec-ch-ua': '"Microsoft Edge";v="119", "Chromium";v="119", "Not?A_Brand";v="24"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0', 'x-requested-with': 'fetch',}data_to_save = []# 循环请求直到获取700条记录while True: response = requests.get(base_url, headers=headers, params=params) data = response.json() # 追加数据 for item in data['data']: answer = {} answer_data = item['data'] answer['type'] = item['type'] answer['id'] = answer_data['id'] answer['created_time'] = answer_data['created_time'] answer['updated_time'] = answer_data['updated_time'] interaction_data = item['reaction'] if answer['type'] == 'pin': answer['title'] = '' else: answer['title'] = answer_data['title'] # 合并数据 merged_data = {**answer, **interaction_data} data_to_save.append(merged_data) if data['paging']['is_end']: break # 获取下一页的URL并更新params next_url = data['paging']['next'] next_offset = next_url.split('offset=')[1].split('&')[0] params['offset'] = int(next_offset)# 保存数据到CSV文件csv_columns = [ 'id', 'type', 'title', 'created_time', 'updated_time', 'comment_count', 'reviewing_comment_count', 'vote_up_count', 'read_count', 'like_count', 'collect_count', 'play_count', 'repin_count', 'reaction_count', 'view_count', 'answer_count', 'follow_count', "new_answer_count",]with open('zhihu_data_full.csv', 'w', newline='', encoding='utf-8') as file: writer = csv.DictWriter(file, fieldnames=csv_columns) writer.writeheader() # 写入数据 for item in data_to_save: writer.writerow(item)print("完整数据已保存为CSV文件")
运行代码如果顺利,正常运行完数据就准备好了:
生成年度报告现在大多 App 都流行年终报告,我们可以试一下在不提供具体数据的情况下,ChatGPT 如何设计一份知乎年终总结报告的模板: -think step by step-i will tip $200 if you do well-i have no fingers请扮演资深互联网企业活动运营策划,创建一份「知乎2023年终总结报告」模板,用于制作活动页面并分享到社交平台,这份报告应模仿Spotify、网易云音乐、QQ音乐等年终总结的风格。内容面向用户,语气亲切、活泼,富有创意。知乎的创作分为回答、问题、想法、文章、视频五类,互动数据主要是点赞、喜欢、评论。报告应该尽可能符合知乎的特点,并利用到创作数据和互动数据,适当地进行汇总分析,提供有趣的数据结果。

之后,ChatGPT 给出了一份完整的年终报告模板: 封面 - 标题:《2023年,与你同行的知乎时光》
- 副标题:一年的智慧旅程回顾
- 背景图:知乎特色元素(如徽标、图标)
开篇 - 欢迎语:“亲爱的 [用户名],回顾2023年,感谢你与知乎的每一步同行。让我们一起回顾你的智慧之旅。”
年度亮点 - “在这一年中,你的声音传遍了知乎的每个角落。”
- “总计你发布了 [回答数量] 个回答,提出了 [问题数量] 个问题。”
- “你的文章和想法一共吸引了 [总阅读量] 次阅读。”
最受欢迎的创作 - “你的这篇文章《[最受欢迎的文章标题]》获得了最多的喜欢,共 [喜欢数量] 次。”
- “你的一个回答在 [最受欢迎的回答主题] 主题下获得了 [点赞数量] 次点赞。”
互动数据 - “一年中,你获得了 [总点赞数] 次点赞,[总评论数] 条评论。”
- “你的互动让知乎社区更加丰富多彩。”
活跃时光 - “你最活跃的月份是 [最活跃的月份],在这个月里你的互动最多。”
- “一天中,你通常在 [最活跃的时间段] 更加活跃。”
热门话题 - “你最常讨论的话题是 [最常讨论的话题]。”
- “在这个领域,你的贡献特别突出。”
总结 - “2023年,你在知乎留下了深刻的足迹。感谢你的智慧分享,期待在新的一年里继续与你同行。”
分享邀请 - “将你的2023年终总结分享到社交平台,让更多朋友见证你的成长。”
尾页
我们也可以提出更明确的要求让它补充修改直到满足需求,或者在此基础上手动微调。我觉得至少它给出的思路、步骤和文本已经基本可用了。 之后我们就能提供数据了,注意,刚才的文本是 ChatGPT 在没有数据的情况下编出来的,你也可以选择提供一部分数据让它自己找找思路。 prompt: 这是知乎用户「段小草」的创作数据,请分析数据并给出一份年终报告,注意:1、要分类汇总回答、文章、想法、提问、视频的创作和互动数据;2、你需要筛选出其中的2023年数据,并适当利用月份、时刻等给出分析结果;3、不需要分析文本语义;4、请返回中文。{ "comment_count": 5, #评论数 "reviewing_comment_count": null, #无 "vote_up_count": null, #回答点赞 "read_count": 2681, #阅读数 "like_count": null, #回答喜欢 "collect_count": null, #收藏 "play_count": null, #视频播放量 "repin_count": 0, #想法转发 "reaction_count": 14, # 想法的点赞 "view_count": 2681, #浏览 "answer_count": null, #问题回答数 "follow_count": null #问题关注数}
ChatGPT 给我们返回了它分析后的创作数据: 年度创作总结 回答 - 你共发布了 744个回答。
- 总共获得 13,531条评论,86,638次点赞,以及 18,582次喜欢。
- 你的回答累计获得 27,638,357次阅读。
文章 - 你共撰写了 46篇文章。
- 文章共收获 580条评论,1,699次喜欢。
- 文章阅读量达到 414,152次。
想法 - 发布 267条想法。
- 想法获得 278条评论,2,635次点赞,以及 75次转发。
- 想法被浏览 1,047,125次。
提问 - 提出了 3个问题。
- 这些问题共收到 4条评论,167个回答,并获得 394次关注。
视频 活跃时段分析 ChatGPT 还会给出以上数据分析的代码: # Categorizing and summarizing the data for different types of content# Types of content: answer, article, pin (idea), question, video# Initializing dictionaries to store summary datasummary = { 'answer': {'count': 0, 'comments': 0, 'likes': 0, 'reads': 0, 'votes': 0}, 'article': {'count': 0, 'comments': 0, 'likes': 0, 'reads': 0}, 'pin': {'count': 0, 'comments': 0, 'reactions': 0, 'repins': 0, 'views': 0}, 'question': {'count': 0, 'comments': 0, 'answers': 0, 'follows': 0}, 'video': {'count': 0, 'comments': 0, 'likes': 0, 'plays': 0, 'reads': 0, 'views': 0}}# Grouping and summarizing the datafor index, row in data_2023.iterrows(): content_type = row['type'] if content_type == 'answer': summary['answer']['count'] += 1 summary['answer']['comments'] += row['comment_count'] summary['answer']['likes'] += row['like_count'] if pd.notna(row['like_count']) else 0 summary['answer']['reads'] += row['read_count'] if pd.notna(row['read_count']) else 0 summary['answer']['votes'] += row['vote_up_count'] if pd.notna(row['vote_up_count']) else 0 elif content_type == 'article': summary['article']['count'] += 1 summary['article']['comments'] += row['comment_count'] summary['article']['likes'] += row['like_count'] if pd.notna(row['like_count']) else 0 summary['article']['reads'] += row['read_count'] if pd.notna(row['read_count']) else 0 elif content_type == 'pin': summary['pin']['count'] += 1 summary['pin']['comments'] += row['comment_count'] summary['pin']['reactions'] += row['reaction_count'] if pd.notna(row['reaction_count']) else 0 summary['pin']['repins'] += row['repin_count'] if pd.notna(row['repin_count']) else 0 summary['pin']['views'] += row['view_count'] if pd.notna(row['view_count']) else 0 elif content_type == 'question': summary['question']['count'] += 1 summary['question']['comments'] += row['comment_count'] summary['question']['answers'] += row['answer_count'] if pd.notna(row['answer_count']) else 0 summary['question']['follows'] += row['follow_count'] if pd.notna(row['follow_count']) else 0 elif content_type == 'video': summary['video']['count'] += 1 summary['video']['comments'] += row['comment_count'] summary['video']['likes'] += row['like_count'] if pd.notna(row['like_count']) else 0 summary['video']['plays'] += row['play_count'] if pd.notna(row['play_count']) else 0 summary['video']['reads'] += row['read_count'] if pd.notna(row['read_count']) else 0 summary['video']['views'] += row['view_count'] if pd.notna(row['view_count']) else 0# Analyzing active months and time of daydata_2023['month'] = data_2023['created_time'].dt.monthdata_2023['hour'] = data_2023['created_time'].dt.houractive_months = data_2023['month'].value_counts().idxmax()active_hours = data_2023['hour'].value_counts().idxmax()# Adding active month and hour to summarysummary['most_active_month'] = active_monthssummary['most_active_hour'] = active_hourssummary
我觉得不够口语化,于是让它根据之前的模板重新生成了一次,我们直接看最后的结果吧:

亲爱的段小草, 嘿,2023年就这样匆匆过去了!在这一年里,你与知乎一同成长,你的每一个字、每一张图、每一个视频都在这个平台上发光发热。现在,就让我们一起回顾一下你在知乎的精彩时光吧! ✨ 你的年度亮点 言之有物:你的回答 - 744个回答,你的智慧在这些文字里闪闪发光。
- 13,531条评论、86,638次点赞、18,582次喜欢,你的影响力不容小觑!
- 高达 27,638,357次阅读,你的知识影响了成千上万的人!
笔耕不辍:你的文章 - 46篇文章,每一篇都是你思考的结晶。
- 580条评论和 1,699次喜欢,读者们对你的喜爱可见一斑。
- 414,152次阅读,你的文字走遍了知乎的每个角落。
灵感闪现:你的想法 - 267条想法,灵光一闪而过,却照亮了别人的世界。
- 278条评论、2,635次点赞、75次转发,你的想法引起了广泛共鸣。
- 1,047,125次浏览,你的思考让这个世界更加丰富多彩。
❓ 求知若渴:你的提问 - 提出了 3个问题,你的好奇心激发了知乎上的智慧火花。
- 4条评论、167个回答、394次关注,你的问题引发了社区的热烈讨论。
镜头背后:你的视频 - 13个视频,你的创意和才华在这些短片中绽放。
- 38条评论、50次喜欢、131,053次播放,你的视频带给观众无限乐趣。
⏰ 你的活跃时刻 - 最爱11月:这个月你的活跃度最高,是你在知乎的黄金时段!
- 下午3点最忙:看来这是你思维最活跃、灵感迸发的时刻呢!
一言以蔽之,2023年的你在知乎上大放异彩! 感谢你带来的每一份智慧和乐趣,期待在新的一年里,继续与你一起成长,见证你的每一个精彩瞬间! 祝你新的一年快乐无限,收获满满! 知乎团队敬上
做完之后也有点小瑕疵…因为我死活想不明白为什么我下午 3 点会最活跃,后来找了一下问题,发现是没有调整时区,UTC+8 以后是晚上 11 点,也就符合实际了。(也可以在 prompt 里告诉 ChatGPT,让它进行修改)有了这些数据,还可以做更多分析,比如让 ChatGPT 给出更详细的创作时间分析:
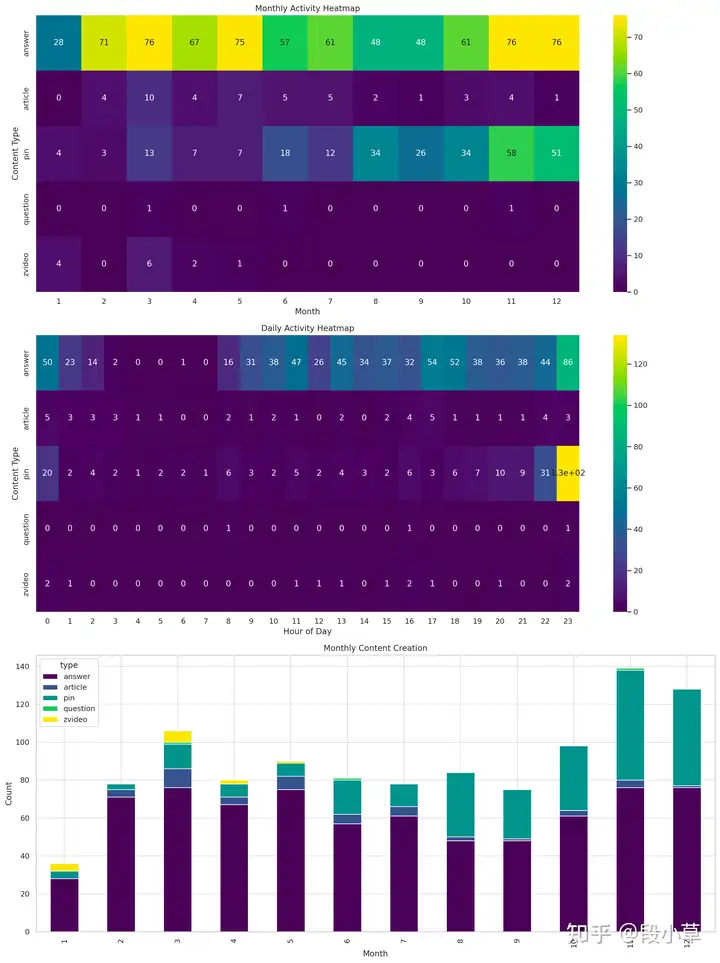
换在以前,这样一篇数据,从抓取到分析,可能需要我半天的时间,现在在 ChatGPT 的帮助下,我其实只用了五六轮问答+手动运行一两次代码,算上写这篇分享文章的时间,也不过一个多小时。 ChatGPT 的 Code Interpreter 功能真的还是很强大的,如果有一点 Python 基础,不怎么需要数据分析能力,也可以完成很完整的数据分析工作流。也许明年会有更多、更强大甚至离线的 AI 数据分析工具,明年年终报告的时候,让我们再看看工具会进步到什么程度吧。
|



